


System development technical roadmap
The construction of the ophthalmic diagnostic intelligent decision support platform required the support of AI technology, first of which was Natural Language Processing (NLP) technology. This involved training NER models using historical medical records, selecting the optimal model, and extracting important diagnostic information from the patient’s EMR. Then, according to the diagnostic rule template, various disease feature vectors were generated, and the XGBoost algorithm of machine learning technology was used to infer the optimal disease diagnosis. The input of XGBoost is the vector of key diagnostic feature words extracted from ophthalmic EMRs, and the output is the recommended ophthalmic disease name for diagnosis. The specific technical roadmap was shown in Fig. 1.
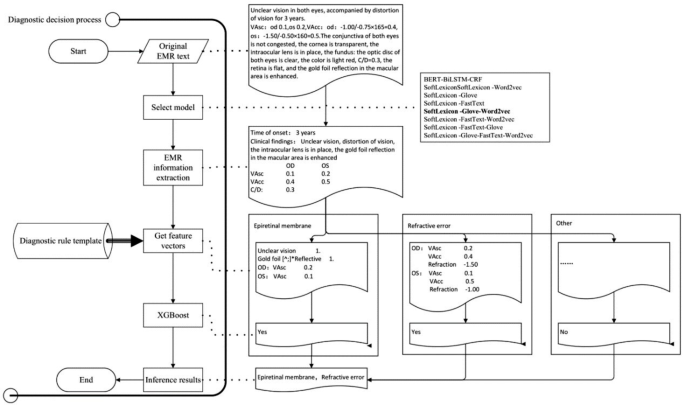
Determination of the best NER model
There are many models related to NER, including commonly used models such as Bidirectional Encoder Representations from Transformers (BERT) [23], Long Short Term Memory (LSTM) [24], and conditional random field (CRF) [25]. To determine the most suitable NER model for ophthalmic electronic medical records, we use the SoftLexicon model proposed by ALC 2020 [26] as the text classification model. This model incorporates dictionary information at the Chinese character level NER model, resulting in good NER performance. By combining different word vector models for effect comparison, we aim to determine the best named entity recognition model for ophthalmic electronic medical record recognition scenarios.
The sample and test set data came from the EMR desensitization database of a tertiary grade-A eye hospital in Zhejiang Province. The time period was from January 2022 to December 2022. Since deep learning-based methods required high-quality labeled data, after the EMRs were cleaned, they were labeled by a professional team of ophthalmic clinical doctors, and the labeled tags were set according to clinically common diagnostic and treatment basis, including chief complaints, history of present illness, past history, systemic disease history, clinical examinations (specialized and supplementary examination) and operative procedures etc. The annotated tags were shown in Table 1. The experiment used 2280 standardized EMRs annotated by a team of ophthalmologists, with 1824 randomly selected as the training set and the remaining 456 as the test set.
In model selection experiment, the Chinese classical NER BERT-BiLSTM-CRF model was used as the baseline model [27, 28], and the SoftLexicon model combined with the word vector Glove, Word2vec and FastText was used as the test model [29, 30]. The evaluation metrics were Precision, Recall, and F1 score, F1 is the harmonic mean of Precision and Recall, which is used to measure the accuracy and recall of the model in general. The formula for calculation is:
$$\text{F}1=2\text{*}\frac{\text{P}\text{r}\text{e}\text{c}\text{i}\text{s}\text{i}\text{o}\text{n}\text{*}\text{R}\text{e}\text{c}\text{a}\text{l}\text{l}}{\text{P}\text{r}\text{e}\text{c}\text{i}\text{s}\text{i}\text{o}\text{n}+\text{R}\text{e}\text{c}\text{a}\text{l}\text{l}}$$
(1)
After comparing different word vectors, the optimal results are shown in Table 2. The computational power and performance of the optimal model and the baseline model were evaluated by the time and GPU days consumed during a single round of training.
The SoftLexicon-Love-Word2vec model with the highest F1 score had a shorter average training times in different batches than the baseline model BERT-BiLSTM-CRF. When inferring 1000 text samples, the SoftLexicon-Glove-Word2vec model took 7.94 s, which was 7.69% faster than the baseline model’s 8.55 s. The search time for the SoftLexicon-Glove-Word2vec model on a 2080Ti GPU was 0.21 GPU days, which was shorter than the baseline model’s 0.27 GPU days on a 2080Ti GPU.
Based on the above experimental results, the SoftLexicon-Glove-Word2vec model was the best model for this study. We used this model to build an ophthalmic diagnostic intelligent decision support platform for fundus diseases.
Development of the diagnostic intelligent decision support platform
Through research and communication with clinical ophthalmologists and based on medical diagnosis practices, we have found that the diagnosis methods for ophthalmology diseases in EMRs generally have distinct distribution characteristics of key feature words. For example, for vitreous hemorrhage, the special examination results will clearly appear with a description containing the term “hemorrhage”. For refractive errors, the chief complaint generally appears with the term “blurred vision” and the supplementary examination results show an uncorrected vision less than 1.0. The diagnostic rule templates for ocular fundus diseases are constructed by analyzing the patterns and relationships among various features extracted from EMRs, such as patient demographics, chief complaint, medical history, and examination results. By identifying significant correlations between these features and specific ocular fundus diseases, we can create rules for disease diagnosis. These templates provide junior doctors with a structured approach to diagnosing ocular fundus diseases.
After extracting feature information from free text EMRs. Based on the diagnostic rule template, generate feature vectors, and then use XGBoost classifier to infer the corresponding disease diagnosis. Using the training set and test set of the above samples, the predictive performance of the XGBoost classifier on the test set is shown in Table 3.
By using NER and AI technology to structurally process EMRs, we could extract and utilize feature vectors. To improve the efficiency and accuracy of clinical ophthalmologists in diagnosing retinal diseases, we developed an ophthalmic diagnostic intelligent decision support platform in combination with the XGBoost algorithm. Figure 2 shows the functional interface of ophthalmic diagnostic intelligent decision support platform and the scenarios of its trial use in the clinic room. In Fig. 2.A, the left side is the input area for electronic medical record information, while the right side is the result display area. After clicking the “Submit” button, the clinical findings column on the right presented the meaningful key medical terms identified by NER for assist diagnosis. The patient’s history of ophthalmic surgery and chronic disease names could also be extracted simultaneously. The numerical feature column displays the ophthalmic examination numerical features related to the EMR. The recommended diagnosis column displays the recommended diagnosis disease names obtained through NER of the key medical terms in the EMR. Clinical doctors could use the recommended diagnosis to better perform diagnosis and treatment work, reduce missed diagnosis and misdiagnosis, and save patients’ visiting time.
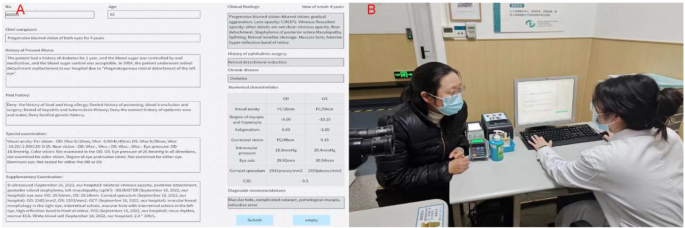
(A): Diagnostic inference interface. (B): The scene of trial use in the clinic room (Consent for publication had been obtained from the doctor and patient in the picture)
Add Comment